Unterstützung #107
offenFormulareingabe auf nicht UTF-8 kodierte Zeichen prüfen
0%
Beschreibung
Ich hab einmal, zum Ausprobieren folgenden Check beim Speichern von Angeboten eingetragen.
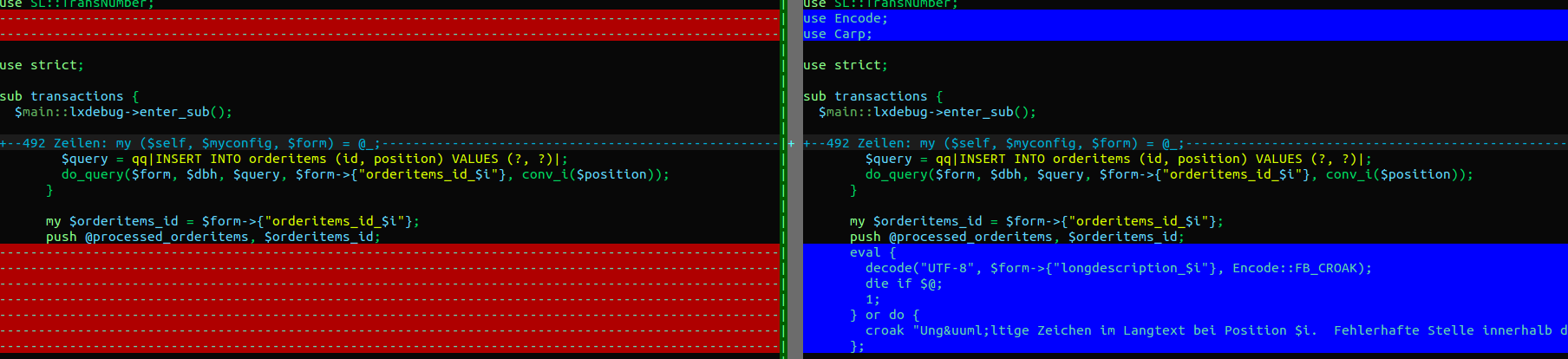
use Encode;
use Carp;
(...)
eval {
decode("UTF-8", $form->{"longdescription_$i"}, Encode::FB_CROAK);
die if $@;
1;
} or do {
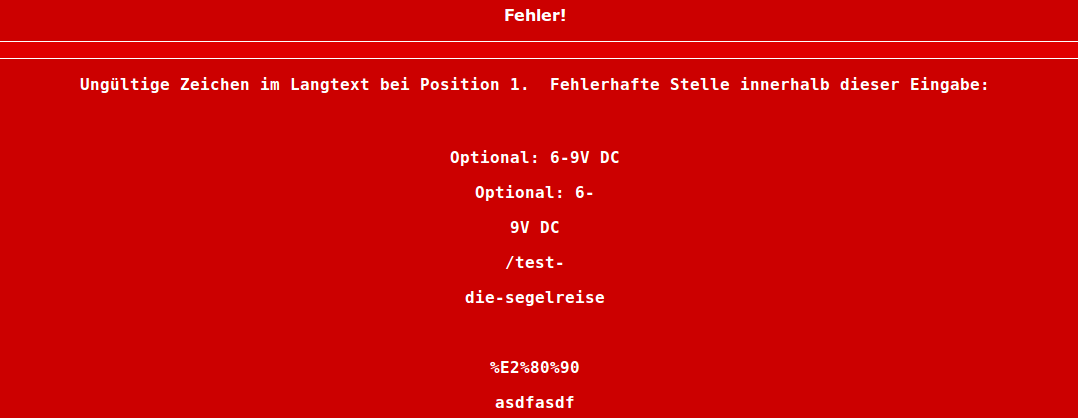
croak "Ungültige Zeichen im Langtext bei Position $i. Fehlerhafte Stelle innerhalb dieser Eingabe:" . $form->{"longdescription_$i"};
};
Und komme dann zu einer Fehlermeldung wie im Anhang beschreiben.
Ich finde das Verhalten um Längen besser, als die lange Fehlerkette von LaTeX, vom Anwender, "parsen" zu lassen.
Im Detail kann/sollte die Prüfung auch anders aussehen (neuer Controller?).
Was ich mir noch wünschen würde, wäre die genaue Stelle des fehlerhaften Zeichens einzugrenzen.
Das hier beschriebene FB_QUIET oder FB_DEFAULT Fehlerhandling lieferte bei mir immer nur die Meldung Zeichenkette enthält wide character, o.ä. zurück:
http://perldoc.perl.org/Encode.html#Handling-Malformed-Data
Offen zur Diskussion ...
Dateien
{kind=link}
{kind=link}
Von Bernd Bleßmann vor mehr als 9 Jahren aktualisiert
Jan Büren schrieb:
Ich finde das Verhalten um Längen besser, als die lange Fehlerkette von LaTeX, vom Anwender, "parsen" zu lassen.
Das Problem hatte ich schon kurz im Chat angesprochen:
Dein problematisches Zeichen war ja ein bestimmter Bindestrich (Hyphen) utf8: 0xE28090: Unicode 0x2010: ‐
Das ist durchaus ein gültiges UTF-8-Zeichen.
Mit Deinem Workaround fängst du auch andere ab, die so schon (durch special_chars) in Latex gesetzt werden können (z.B. den left-arrow: utf8: 0xE28690: Unicode 0x2190: ←), die also funktionieren.
Wie mosu sagt, ist nicht falsches utf8 das Problem, sondern latex weiß nichts damit anzufangen.
Von Jan Büren vor mehr als 9 Jahren aktualisiert
Ich hab die special_chars versuchsweise mal probiert "whitezulisten", allerdings gelingt mir dies auf Anhieb nicht:
Falls der eval-Block einen Fehler wirft, entsprechend noch vorher prüfen, ob wir diese Zeichen nicht in special_chars parsebar zu Verfügung haben:
# whitelist versuch an dieser stelle
croak "Ungültige Zeichen im Langtext bei Position $i. Fehlerhafte Stelle innerhalb dieser Eingabe:" . $form->{"longdescription_$i"}
unless $form->{"longdescription_$i"} =~ m/(±|²|³|°|§|®|©|\xad|\xa0|➔|→ |←|−|≤|≥|≤)/;
Wenn ich mir den Wert der longdescription in die debug-Datei schreibe und diesen testweise überprüfe, funktioniert alles einwandfrei:
my $long =" was hier:<p><br />≤ test</p>";
unless ($long =~ m/(±|²|³|°|§|®|©|\xad|\xa0|➔|→ |←|−|≤|≥)/) {
print "blub";
}
Von Jan Büren vor etwa 1 Jahr aktualisiert
Noch die Ergänzung von Sven von damals dazu:
Comment (by s.schoeling@…):
Das sind aber zwei verschiedene paar Schuhe Jan.Der Artikel den Du gelinkt hast geht um invalid UTF8, sprich Bytesequenzen
die nicht korrektes UTF8 sind, sondern binärer Müll. Das ist aber nicht
das was beim Drucken auftritt.Was beim LaTeX Drucken Probleme macht sind valide UTF-8 Zeichen, für die
LaTeX nur keine Glyphe parat hat. Sehr häufig ist das ' ' (U+00A0 NO-
BREAK-SPACE, wird aus generiert), typographische Anfühungszeichen
wie sie MS-Office ungefragterweise in allem generiert (‘ ’ ‚ “ ” „),
irgendwelcher anderer typographischer Müll der in solchen Strings
eigentlich nichts zu suchen hat (ff - LATIN SMALL LIGATURE FF), oder
einfach mal Zeichen auf den wilden Weiten von Unicode (�, �, ℞. �, �. �,
文)Ich hab mich da schonmal mit beschäftigt, und es ist sehr schwer a priori
rauszufinden was LaTeX kann und was nicht. Locales und Sprachpakete können
Zeichen, andere funktionieren einfach so, andere lassen das in jeder Form
abkacken.